[Deep Learning] My Notes on the mathematical building blocks of neural networks (Part-1)
In this blogpost, I cover my notes on chapter-2 of the book “Deep learning using python”, by François Chollet, Manning Publications Co., Second Edition, 2020. The author of this book is creator and main contributor for the widely used Python based deep learning library namely Keras. This book is updated and provides an intuitive as well as practical approach towards deep learning. I recommend readers to read the first chapter of this book to get an overall idea about deep learning area.
TOC
-
A first example of a neural network
-
Tensors and tensor operations
-
How neural networks learn via backpropagation and gradient descent
This chapter provides an intuitive understanding of the mathematical theory behind deep learning through executatable code. It covers the intuitive understanding behind concepts such tensors, tensor operations, differentiation, gradient descent etc.
A first example of a neural network or “Hello World” of Deep Learning
Problem: Classifying handwritten digit images of the MNIST dataset into 10 classes (0,1,…9). The dataset description is as follows:
Number of training images: 60000
Number of testing images: 10000
Number of classes: 10
Class Label: {0,1,2,3,4,5,6,7,8,9}
Link to download: http://yann.lecun.com/exdb/mnist/

Sample images from the dataset.
This MNIST dataset comes preloaded in the Keras library. Keras is ranked as #1 for deep learning both among primary frameworks and among all frameworks used as per the Kaggle survey and there are over 375,000 individual users of this library as of early 2020 [1].
What is Keras?
Vertatim from its documentation
Keras is a deep learning API written in Python, running on top of the machine learning platform TensorFlow. It was developed with a focus on enabling fast experimentation. Being able to go from idea to result as fast as possible is key to doing good research.
Author starts by explaining the Keras implementation for above problem step by step using the code snippets. The complete program is as follows:
# Step1: Loading the MNIST dataset in Keras
from keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# Shape of training and testing images
print(train_images.shape)
print(test_images.shape)
# Number of samples in training and testing datasets
print(len(train_images)
print(len(test_images)
# Step2: Setting up Network Architecture
from tensorflow.keras import models
from tensorflow.keras import layers
model = models.Sequential([
layers.Dense(512, activation='relu'),
layers.Dense(10, activation='softmax')
])
# Step3: The compilation step
model.compile(optimizer='rmsprop', loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Step4: Preparing the image data
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype('float32') / 255
# Step5: Fitting the model
model.fit(train_images, train_labels, epochs=5, batch_size=128)
# Step6: Evaluating the model on new data
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('test_acc:', test_acc)
In step1, the MNIST dataset is loaded in terms of train_images, train_labels, test_images and test_labels which are all numpy arrays. The images and labels have one to one correspondence.
In step2, a data processing module having a sequence of two fully connecteddense layers is defined providing both useful feature extraction and their representation. Filtering properties of these two layers depend largely upon their activation functions. For example, the last layer which is a softmax classification layer provides an array of probability scores for 10 classes.
Questions I got in step-2:
What is use of activation function in network layer definition?
Why the layers used are dense (or fully connected)?
Are two layers sufficient for this problem?
In step3 i.e., compilation step, an optimizer, a loss function and a metrics to monitor training and test phases are defined.
Questions I got in step-2:
What is optimizer in deep learning?
What is a loss function in deep learning?
What is metrics in deep learning?
I had encoured explanation for aove questions while reading the first chapter. As per that answers are as follows:
What is optimizer in deep learning?
in deep learning, the each layer has weights associated with it and the key idea is to learn the optimal weight parameters so that network will correctly map example inputs to their associated targets. These weights are adjusted iteratively based on some feedback signal obtained from the score of some loss function in a direction that will lower the loss score in the next iteration and so on. The weight adjustment is the job of an optimizer. optimizer does this by using the backpropogation algorithm, one of the most celebrated algorithm used in modern neural network implementations. See figure below for understanding the role of optimizer.
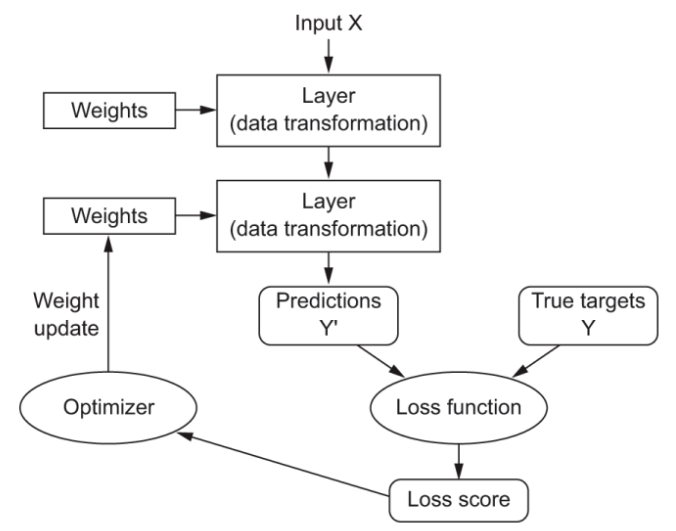
Figure Reference: [2]
What is a loss function in deep learning?
The loss function takes the predictions of the network and the true target (what you
wanted the network to output) and computes a distance score, capturing how well the network has done the learning part for the given dataset [2]
What is Learning: In the context of deep learning, it means finding a set of values for the weights of all layers in a network, such that the network will correctly map example inputs to their associated targets.
What is metrics in deep learning?
Metrics are parameters used to evaluate the final performance of a model such as accuracy, precision, recall etc.
In Step4, the data is preprocessed for training purposes by reshaping, scaling and data type conversion to make it in the proper form as per model requirements. In this case, data was transformed into float32 format with training shape as $(60000, 28\times28)$ i.e., $(60000, 784)$ with values between 0 and 1.
Following are some of the questions I felt for this step.
Why there is a need for scaling the images to 0 to 1? How it helps?
Why reshaping?
Why data type conversion?
Hopefully in the upcoming chapters I will get the answers for these questions.
In step5, the model is fit to its training data.
Following are few questions I felt for this step.
What is epoch in deep learning?
What is batch size?
Why and how these two parameters (epoch & batch size) matter for training?
In step6, the model is evaluated on the new data (test) not used during the training to guage its generalization sanctity over future/unkown data.
References:
[2] “What is deep learning?”, Chapter-1 of “Deep Learning with Python” by François Chollet, Manning Publications Co., Second Edition.