[Deep Learning] Using OpenCV as deep learning inference engine with application to image classification
Deep neural networks i.e., dnn module of OpenCV supports models trained using TensorFlow, Caffe and Pytorch frameworks. In order to make the inference from the pre-trained models in OpenCV, the images are first preprocessed using function blobFromImages() or blobFromImage() which will output a blob. This blob is then provided as input to the trained model to get the inference output.
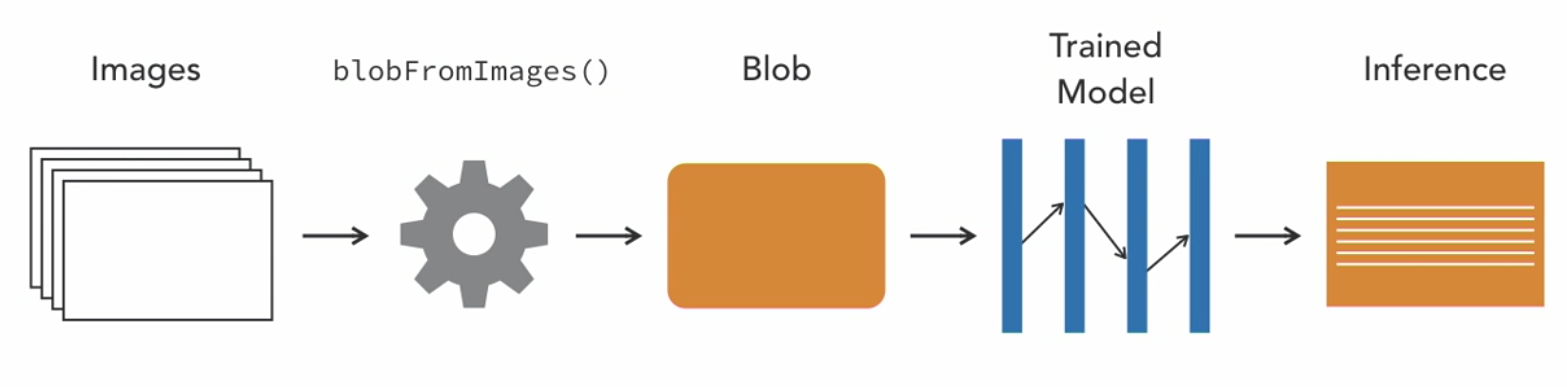
The following functions are useful for our purpose:
net = cv2.dnn.readNetFrom...(...)blob = cv2.dnn.blobFromImage(...)net.setInput(blob)out = net.forword()
For example, if we want to use a Caffe model defined using two files protxt and caffeModel containing information related to the structure of the neural network and the weights of the layers of the neural network, respectively for inference on a single image as input then the sequence of steps to infer the output out would be as follows:
Read the model
cv2.dnn.readNetFromCaffe(protxt, caffeModel)
Create the four-dimensional blob
blob = cv2.dnn.blobFromImage([image], [scalefactor],[size],[mean],[swapRB],[crop],[ddepth])
Setting blob as input to the network
net.setInput(blob)
Forward pass through the network
out = net.forward()
Working with blob
The blob in this case is nothing but one or more images of same width, height and number of channels all which have been preprocessed in the same way.
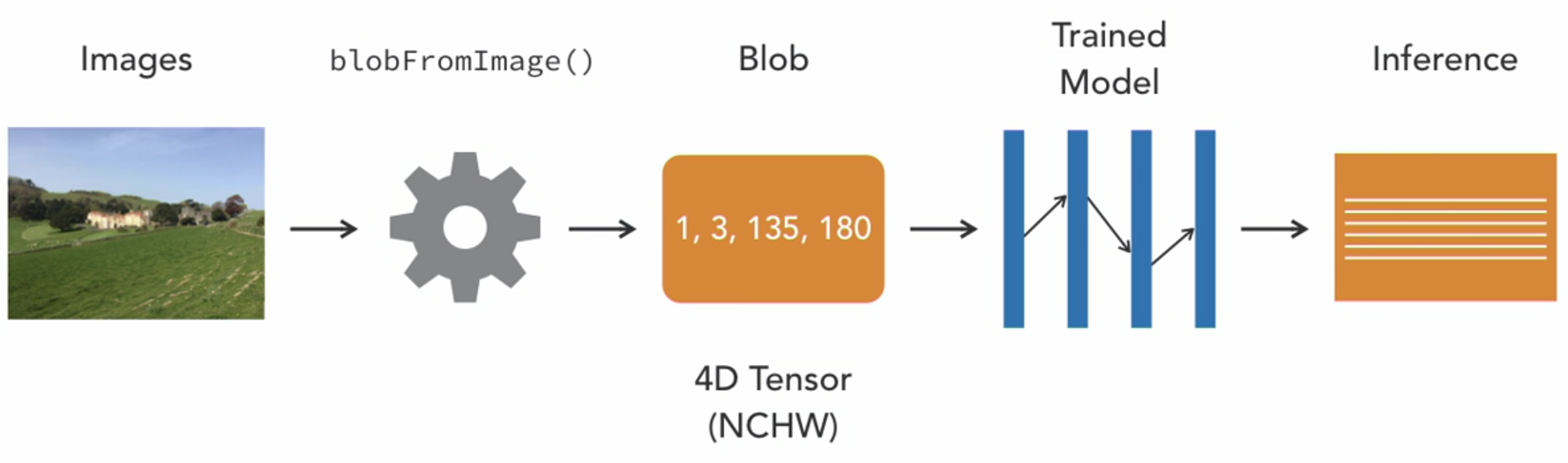 Blob is a 4-D tensor (NCHW) with N: number of image(s), C: number of channel(s), H: height of the image(s) and W: width of the image(s).
Blob is a 4-D tensor (NCHW) with N: number of image(s), C: number of channel(s), H: height of the image(s) and W: width of the image(s).
Following are the parameters one can use with blobFromImage() or blobFromImages() function.

Image classification using OpenCV dnn module
In this section,we will demonstrate the use of OpenCVs dnn module as deep learning inference engine. We will use this for the image classification task using pre-trained Caffe model namely BVLC GoogleNet trained on the famous ImageNet dataset containing 1000 classes. The classes available in the ImageNet dataset can be viewed using synset_word.txt file showing unique id of the class and multiple synonymous words describing that class.
As part of the classsification task, let us read the image to be classified which contains mountains, hills etc.

The preprocessing code before inference part looks as follows:
This file shows the use of OpenCVs dnn module as deep learning inference engine. We will use this for the image classification task using pre-trained Caffe model namely BVLC GoogleNet trained on the famous ImageNet dataset containing 1000 classes.
'''
import numpy as np
import cv2
# Read the image
image = cv2.imread('./images/mountain.jpeg')
# Read the synset_words.txt file
all_rows = open('./model/synset_words.txt').read().strip().split('\n')
print(type(all_rows)) # it's a list
# Using list comprehension to drop ids
classes = [r[r.find(' ')+1:] for r in all_rows]
print(len(classes)) # verify there are 1000 classes
Next we need to implement the inference part using following steps:
- Reading the model
- Creating the four-dimensional blob
- Setting blob as input to the network
- Applying forward pass through the network to get the output
Reading the model
The model that we are going to use is the Caffe model trained on 1000 classes of the ImageNet dataset which is available freely at model zoo.
The model is defined using two files with .prototxt and .caffemodel extensions, respectively.
The model is read as follows:
net = cv2.dnn.readNetFromCaffe('./model/bvlc_googlenet.prototxt','./model/bvlc_googlenet.caffemodel')
The next step is to create a 4-D blob which is used as input to the model.
Creating the four-dimensional blob
The requirements for the input blob to the network can be obtained from the prototxt file which looks as follows for this model:

The red reactangular box shows specifications of the input blob.
We require input blob of dimension (1,3,224,224) where 1 represents number of image(s), 3 represents number of channels and the next two values represents width and height, respectively.
This can be achieved by converting input image to the 4-D blob as
blob = cv2.dnn.blobFromImage(image, 1, (224,224))
next we need to set blob as input to the model.
Setting blob as input to the network
The 4-D blob created from input image can be set as input using:
net.setInput(blob)
next we need to infer the output using forward pass through the network.
Forward pass through the network
The output image is inferred as
out = net.forward().
The out in this case is a numpy array showing probability value for each class. We will first sort its indices in descending order and then choose the first 5 entries and then print their classes.
Code for these operations is as follows:
# Let us grab the top5 probability indices
idx_asc = out.argsort()
idx_desc = np.fliplr(idx_asc)
idx_top5 = idx_desc[0,:5]
# Lets print the final results
for i, id in enumerate(idx_top5):
print("{}. {} ({}): Probability {:.3}%".format(i+1, classes[id], id, out[0,id]*100))
The output produced is as follows:
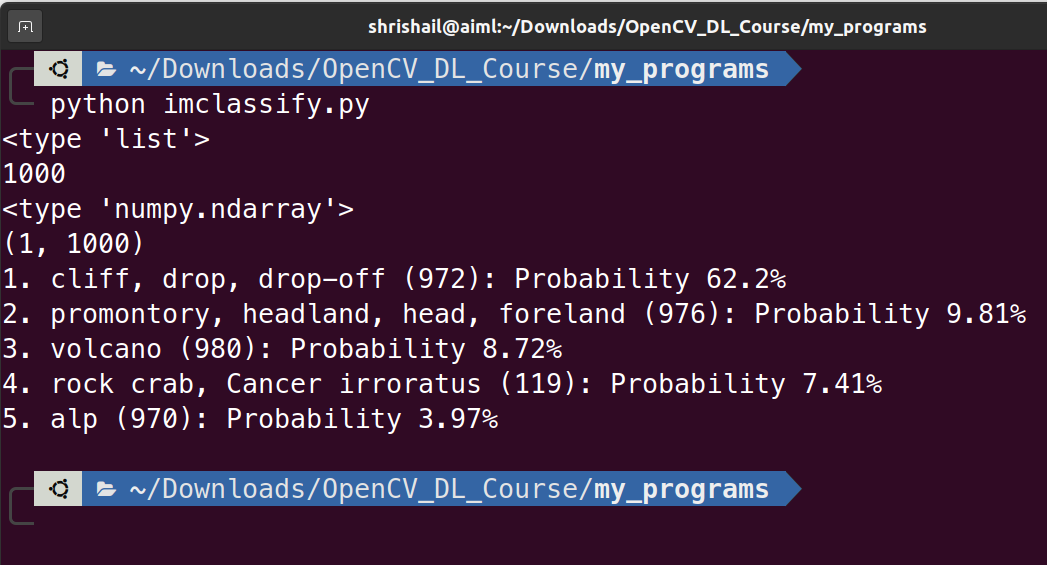
One can see that, the first predicted class with 62.2% probability is cliff which is correct.
The complete program is as follows:
# Filename: imclassify.py
'''
This file shows the use of OpenCVs dnn module as deep learning inference engine. We will use this for the image classification task using pre-trained Caffe model namely BVLC GoogleNet trained on the famous ImageNet dataset containing 1000 classes.
'''
import numpy as np
import cv2
# Read the image
image = cv2.imread('./images/mountain.jpeg')
# Read the synset_words.txt file
all_rows = open('./model/synset_words.txt').read().strip().split('\n')
print(type(all_rows)) # it's a list
# Using list comprehension to drop ids
classes = [r[r.find(' ')+1:] for r in all_rows]
print(len(classes)) # verify there are 1000 classes
net = cv2.dnn.readNetFromCaffe('./model/bvlc_googlenet.prototxt','./model/bvlc_googlenet.caffemodel')
blob = cv2.dnn.blobFromImage(image, 1, (224,224))
net.setInput(blob)
out = net.forward()
# The out in this case is a numpy array
print(type(out))
print(out.shape)
# Let us grab the top5 probability indices
idx_asc = out.argsort()
idx_desc = np.fliplr(idx_asc)
idx_top5 = idx_desc[0,:5]
# Lets print the final results
for i, id in enumerate(idx_top5):
print("{}. {} ({}): Probability {:.3}%".format(i+1, classes[id], id, out[0,id]*100))
To run the program type python imclassify.py at the terminal.
Reference:
- https://www.lynda.com/OpenCV-tutorials/Introduction-Deep-Learning-OpenCV/5034175-2.html